Non-Commodity Content: The Framework B2B Teams Need in 2026
Google now publicly distinguishes "commodity" content (replaceable by AI or any competitor) from "non-commodity" content (irreplaceable). Most B2B sites are still publishing the former and wondering why their clicks are vanishing.
By Baba Hausmann · Non-Commodity Score: 14/15 · Last updated April 2026

What is non-commodity content?
Non-commodity content is content that can't be reproduced by a competitor or an AI, because it's built from raw material only you have: your data, your customer conversations, your failures. Google's guidance now explicitly rewards it. If a page could be generated from public information alone, it's commodity content.
Commodity vs non-commodity content
The distinction sounds abstract until you put two pages side by side.
| Commodity content | Non-commodity content | |
|---|---|---|
| Source | Public information anyone can access | Your data, your clients, your experience |
| Who can make it | Any competitor, or any AI, today | Nobody without your raw material |
| What Google does with it | Dislocated by AI Overviews | Cited, ranked, and shown |
| Example | A "what is X" explainer stitched from the top 10 results | A teardown with your own Q1 numbers and what went wrong |
Your rankings held. Your clicks vanished. Here's why.
If you run SEO for a B2B company, you've probably watched this happen in your last quarter's data. Your commercial pages still rank where they used to. Some of them rank slightly better. The clicks are gone anyway.
I work with two B2B companies where this happened across Q1 2026 in different categories. One a Dutch SME lender, one a B2B equipment company in workplace water. The pattern is identical.
Rankings: holding or improving by ~2 positions on average.
CTR: down 35-72% across the commercial page set.
The lender's flagship commercial page held position 1 organically on a key category query while losing 62% of its clicks. The equipment company watched their highest-CPC commercial keyword (€19+ CPC, real money) sit at position 30. Not because they couldn't rank, but because what was ranking was the wrong page.
This is not a Core Update story. Their pages didn't get demoted. The SERP got rearranged around them.
Most SEO advice for this moment is wrong. "Update your content," "add EEAT signals," "use more AI for scale." None of those address the actual mechanism.
If your non-brand commercial pages dropped more than 30% in clicks this quarter while rankings held, your content is being read as commodity. This will not reverse with optimization tweaks. It reverses only with a different kind of content.
What Google's Search Central team said about commodity content
Google's Search Central team presented the framing publicly in April 2026. Two slides matter.
Slide 1: "Good Non-Commodity content is"

- Unique: brings a viewpoint, information or has content that others lack or can't easily replicate
- Specific: talks about a specific instance, situation or thing, not general rules, steps or generic information
- Authentic: demonstrates first-hand knowledge or experience
Slide 2: Commodity vs Non-Commodity

The slide compared real categories. A running store's "Top 10 Things to Consider When Buying Running Shoes" is commodity. A running store's "Why This Customer's Shoes Collapsed After 400 Miles: A Wear Pattern Analysis" is non-commodity. Same category, same expertise, totally different content.
What Danny Sullivan didn't say but every B2B operator should hear: "unique" doesn't mean "a different angle on the same information." It means information no one else has access to.
In the same event, Google confirmed that high-volume AI-generated content is now treated as scaled content abuse. Commodity content isn't just being ignored. It's being penalized.
Why commodity content stopped working in 2026 specifically
Most readers know AI Overviews exist. Few have connected the mechanism cleanly to commodity content collapse.
AI Overviews can assemble an answer for a generic commercial query from eight commodity sources without needing any single one specifically. The Dutch lender I mentioned: their flagship product page on a category query showed an AI Overview citing eight competitors zero times. Not "ranked low." Not cited. The AIO didn't need them.
Same companies on a more specific query — one tied to a named customer story or a first-hand decision — the AIO either cites them or doesn't render at all. The content that survives is the content the AIO can't compress without losing meaning.
This is the actual mechanism. AI Overviews are a commodity-content compressor. They take eight average pages saying the same thing and produce a summary that no single page beats. The pages keep their rankings. The clicks go to the summary instead.
This isn't a Google update you adapt to with tactics. The economics of commodity content have permanently changed. Pages that used to lose 20% CTR to featured snippets now lose 40-60% to AI Overviews. The losses compound with each update.
The B2B equipment company's data shows the same pattern from a different angle. They have 199 ranked non-brand keywords. Only 21 carry commercial intent. The other 178 are informational queries — "best XYZ in the world," that kind of thing — where they show up but no one buys. AI Overviews ate the informational queries first, because those are the most commodity-shaped. The commercial queries followed.
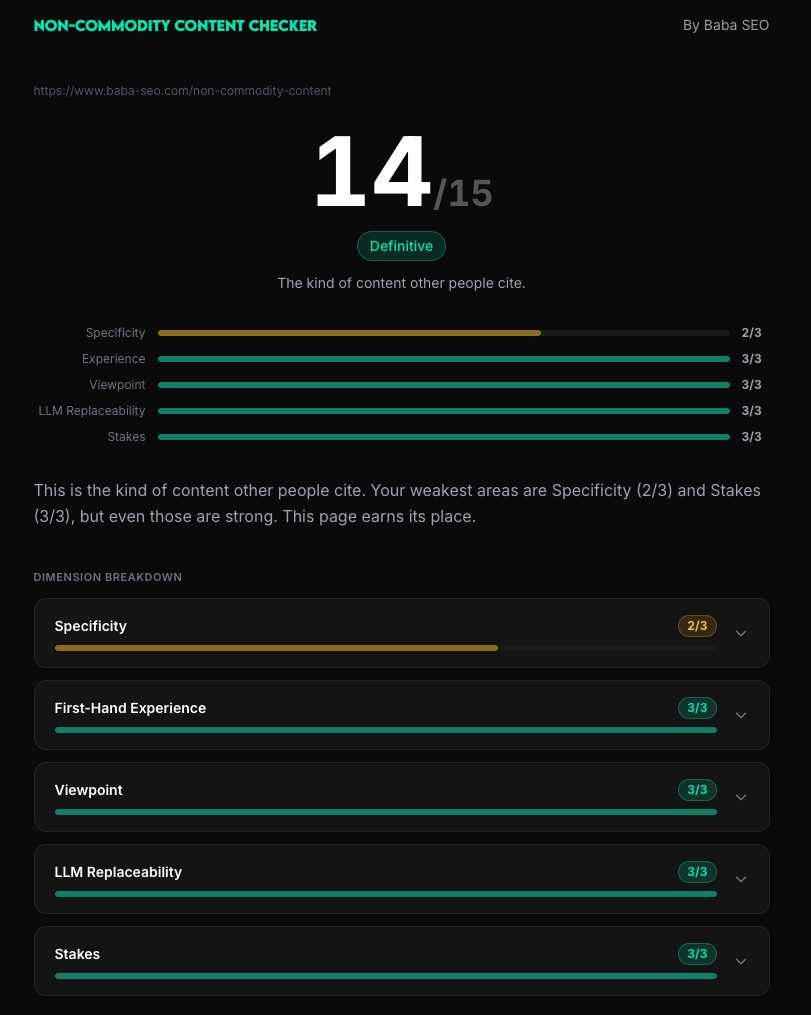
So what is non-commodity content, specifically? Five dimensions.
The five dimensions of non-commodity content
Google's "unique, specific, authentic" framing is directionally right but too vague to audit against. The way I think about it for B2B content is five dimensions, each scored 0-3.
A page scoring 0-4 is commodity. 5-8 is mostly commodity. 9-11 is differentiated. 12-15 is the kind of content other people cite.
Specificity

Named instances, exact figures, verifiable particulars.
Looks like: "We helped a B2B SaaS company in a regulated category grow organic traffic from 12K to 52K monthly sessions over nine months, driven by 47 new MOFU pages."
Fails like: "Our clients see significant SEO improvements within a few months."
Diagnostic question: Find the most specific claim on your page. Could you swap out the brand name and republish it on a competitor's site without changing anything?
First-Hand Experience
Evidence the author actually did the thing being described.
Looks like: "On a 2,000-page payments-company migration I led, we caught a canonical tag bug on day three that was silently redirecting roughly 400 product pages to the homepage."
Fails like: "SEO migrations require careful planning."
Diagnostic question: What proof exists on the page that the author actually did what they're describing?
Viewpoint
Positions someone could disagree with.
Looks like: "Most SEO audits are theater. If the deliverable is a 60-page PDF, you hired the wrong person. A real audit names the three pages costing you money and tells you what to do about them by Friday."
Fails like: "Quality content matters more than quantity."
Diagnostic question: Is there a sentence on this page a competitor in your industry would refuse to publish?
LLM Replaceability
How much an LLM with no web access could reproduce from priors.
Looks like: a piece on a specific named deal you closed last week, with a customer quote and the reasoning that drove the decision.
Fails like: a piece on "10 SEO tips for SaaS." An LLM with zero web access could write 95% of that from training data.
Diagnostic question: If you fed your title and outline to a frontier LLM with no search, how close would the output be to what you actually published?
Stakes
What the author is risking by publishing this.
Looks like: "If your B2B SaaS does under €50k MRR, SEO is usually the wrong channel. I say this knowing it costs me leads, but I'd rather be right than be hired."
Fails like: "Every situation is different. It depends on your goals."
Diagnostic question: What is the author putting at risk by publishing this? A reputation claim? A refusal? A number they can be held to?
Want to see how a specific page scores? The Non-Commodity Content Checker runs any URL through this five-dimension rubric and tells you where it's commodity, where it's non-commodity, and what's missing.
Free, no signup to see your score.
Score my content →
Two pages scored, side by side
The framework is more useful applied than described. Two real categories of content, scored against the rubric.
Example
"10 SEO Tips for Small Businesses" — generic listicle, no byline, AI-paraphrased advice
A first-hand SEO migration case study with specific page counts, a named bug caught on day three, and a public commitment ("zero traffic dip")
Specificity
0/3 — generic, "many businesses," round numbers
3/3 — 2,011 pages, day three, 400 product pages affected
First-Hand Experience
0/3 — no author byline, no claim of doing the work
3/3 — named author led the project, named bug, named outcome
Viewpoint
0/3 — pure consensus, hedged everywhere
3/3 — defends a specific approach, willing to disagree with conventional advice
LLM Replaceability
1/3 — 95% reproducible from training priors
3/3 — fundamentally requires access an LLM doesn't have
Stakes
0/3 — hedged throughout, accountable to nobody
3/3 — falsifiable claim ("zero traffic dip"), reputation on the line
Total
1/15
14/15
Most B2B content sits between these two extremes. It cites real sources and uses real numbers — which feels rigorous — and still scores in the 5-8 range because it lacks first-hand stakes. The author is summarizing and explaining, not committing. That's the most common failure mode in the cluster, and the hardest to spot from inside.
This isn't just EEAT in new clothing
If you've spent any time in SEO conversations, you've heard EEAT — Experience, Expertise, Authoritativeness, Trustworthiness. Reasonable question: isn't non-commodity content the same idea?
It isn't. The two overlap, but they answer different questions.
What it asks
Can we trust the author or site?
Is this piece replaceable?
What it measures
Author credentials, site reputation, expertise signals
Content properties: specificity, viewpoint, stakes
Who it's about
The creator
The piece itself
What good looks like
A credentialed expert publishing on a high-authority site
A piece an LLM and a competitor both struggle to reproduce
If your content is commodity, here's the first three moves
Diagnosing commodity is easier than fixing it. The fix isn't tactical — it's organizational. Three moves, in order.
1. Audit your worst-bleeding page first, not your best-performing one.
Use the Non-Commodity Content Checker. The pages that lost the most clicks while keeping rankings are your highest-leverage rebuilds. They have proven search demand. The only thing missing is non-commodity material. Score them against the five dimensions. The dimension scoring zero is where you start.
Most teams do this backwards. They optimize the page already winning and ignore the page bleeding. Bleeding pages are gold — Google still ranks them, the audience is there, the conversion mechanism has just been removed by the SERP rearranging around them.
2. Build a sourcing pipeline before you write.
Non-commodity content needs raw material that doesn't exist in training data. From the lender's playbook: one customer interview per month, signed permission, specific usage data, two or three photos. One interview per month fuels a year of non-commodity pages.
The organizational lift of capturing that material is bigger than the writing itself. This is the part most content teams skip and then wonder why their non-commodity pages still feel generic. The writing isn't the problem. The inputs are.
3. Stop publishing anything that fails the test.
The equipment company killed 30+ commodity blog posts in Q1 to free up their content lead's time for two strategic priorities: rebuilding the highest-CPC commercial page and writing two new commercial pages where none existed. Volume-as-floor was a 2024 strategy. In 2026, every piece must answer: "what does this company know that a competitor doesn't?"
If a piece can't answer that, it doesn't enter the pipeline. The hardest part of this move is cultural — "we publish two pieces a week" is easy to defend internally; "we publish two pieces a month, all of which would survive an LLM rewriting them" is harder to defend until the data starts vindicating it.
Closing
Commodity content is being dislocated by AI Overviews. Non-commodity content is the only thing that survives. The five-dimension rubric is how you tell the difference, page by page, before Google does it for you.
Two final notes.
The rubric isn't static. I'm calibrating it against many pieces test set spanning known-good and known-bad content, and updating the prompts as I find dimensions that drift. Treat any score you get as directional, not final. The framework will sharpen through 2026.
And if you're reading this thinking your content is commodity, that's the right starting place. Most B2B content is. The companies that move first on rebuilding to the non-commodity standard will be the ones still ranking — and earning clicks — in 2027.
Want the shorter, symptom-first version of this argument? Start with why your B2B content stopped earning clicks. And if you want a second pair of eyes on where your library sits, scoring pages against this rubric is how my B2B SEO consulting engagements usually start — the HealthTech client story shows what rebuilding to this standard did to conversions.
Non-commodity content FAQs
What is commodity and non-commodity content?
Commodity content restates information that already exists publicly, so anyone (or any AI) can produce it. Non-commodity content is built from material only you have: first-party data, client work, lessons learned. Google introduced the distinction to describe what survives AI-generated search results.
How do you make content non-commodity?
Score the page against the five dimensions above: specificity, first-hand experience, viewpoint, LLM replaceability, and stakes. Most commodity content fails on first-hand experience and stakes, the two dimensions that require you to have actually done the work and be willing to be held to a claim. Start with the page bleeding the most clicks, since it already has proven search demand and just needs the raw material a competitor or an AI can't get.
WHAT THIS MEANS

Rankings stable, clicks gone = your content is commodity.
AI Overviews compress what your competitors say into one summary.
Five dimensions tell you which side your content is on.
SCORE YOUR OWN CONTENT.
Run any URL through the Non-Commodity Content Checker. Free, no signup to see your score.


